0x01 概述
OSQuery 是一款由 facebook 开源的,面向 OSX 和 Linux 的监控与分析工具。OSQuery 允许使用 SQL 的方式来获取系统的相关信息,比如正在运行的进程,已加载的内核模块,已打开的网络连接,硬件事件等等。

OSQuery 拥有较高的社区活跃度,目前在 Github 上有一万多 star,四千多次 commit,两百多个开发者。大多数 issue 都能及时解决(这是亲身经历,感谢开发者的答疑解惑)。
理想状况下,OSQuery 作为 HIDS,线上运行时的整体架构应该是这样的:
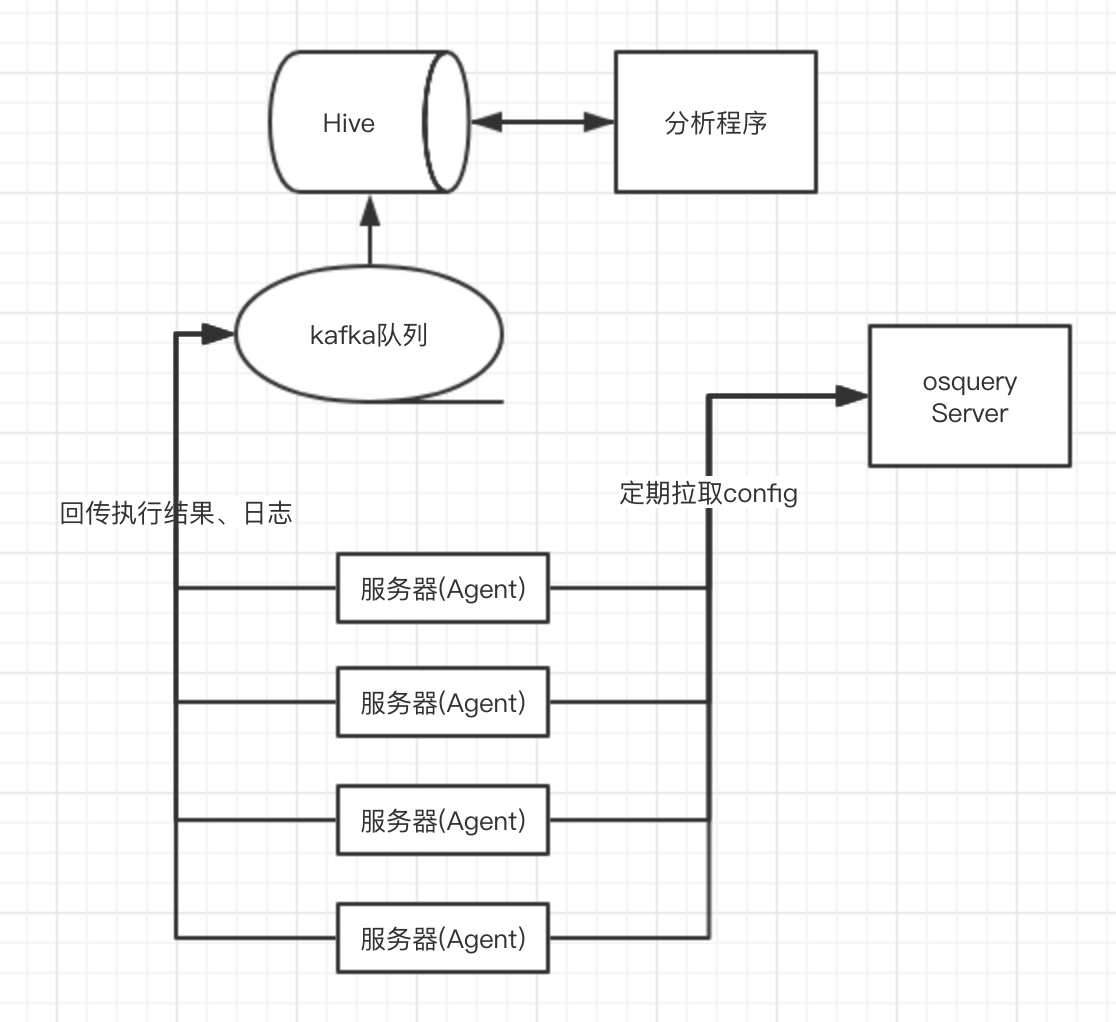
其中,回传队列、日志存储可以根据公司的现状进行调整。比如,用 rsyslog 替换 kafka,ElasticSearch/ClickHouse 替换 Hive 等等。
OSQuery 本身只包含服务器上安装的 Agent,但是提供了丰富的配置项:
- 支持配置远程 Server,调用 http 接口拉取最新的配置文件(包括采集规则、Agent基础配置),并实时生效
- 支持多种日志回传方式,比如 syslog、kafka、filesystem、tls 等
- 支持实时语句的下发,语句拉取及结果回传都走 http(s) 接口,适合调试及单次执行(实测,非常有用)
OSQuery 提供了 200+ 数据表供查询:https://osquery.io/schema/3.3.0,数据来源也非常丰富:
- 直接读取文件,如:users、dns_resolvers、user_ssh_keys
- 执行系统命令,如:logged_in_users、deb_packages
- audit,如:process_events、socket_events、user_events
- inotify,如:file_events
- syslog,如:syslog_events
如果 200 多张表仍然不能满足你的需求,可以通过编写插件来扩展。但是就不能热更新(直接通过 Server 端下发)了,需要更新 Agent 本身,并且重启相关服务。
OSQuery 安装后,会占用两个目录:
- /etc/osquery/: osquery bin文件及部分配置文件
- /var/osquery/osquery.db/: osquery本地存储
OSQuery 是支持差异回传的,比如:
"users_snapshot": {
"interval": 86400,
"platform": "all",
"query": "SELECT * FROM users;",
"removed": true,
"shard": 100
}
每隔 60s 执行一次获取系统用户,第一次执行时会回传所有的用户,第二次执行如果没有新增用户,就不会再回传信息。当然这是一个可选项,添加 snapshot: true 属性后,就可以禁用差异回传的功能。
为了实现这个功能,OSQuery 需要在 Agent 上存储历史数据,使用的是同样由 facebook 开源的 RocksDB。这是一个 key-value 形式的高速存储数据库,默认目录在 /var/osquery/osquery.db/。RocksDB 没有提供像 redis-cli 的 client,但是可以利用第三方工具读取 .sst 文件的内容。
正常情况下,日志会自动滚动存储(Log rotate),每次执行语句都会删除旧的记录,将新的结果存下来。但是有一个例外,就是 audit events 数据。audit events记录是通过限制总条数来进行的。但是这个地方的逻辑似乎存在一些问题,有时候会出现大量events日志未删除的情况(https://github.com/facebook/osquery/issues/5310),导致占用磁盘过高的问题。
暂且不提 bug 的事情,后面统一归纳总结。我们继续讲 audit 这个磨人的小妖精。
0x02 不得不说的Audit
Audit 是 Linux 内核中的一个模块,内核的运行情况、各类系统调用(syscall)都会在 audit 中记录。在 CentOS 的各个发行版中均默认安装了 Audit,在 CentOS7 中还会默认启动 Auditd 进程,负责通过 netlink 与 Audit 模块建立连接,并且将指定的数据记录在磁盘中(默认路径为:/var/log/auditd/audit.log)。
当然默认是没有任何规则的,你可以用 auditctl 命令添加一条规则查看所有的进程:
auditctl -a always,exit -F arch=b64 -S execve
tail -f /var/log/auditd/audit.log
这也是 Audit 在入侵检测中最重要的功能之一,记录进程信息。对于新一代的 HIDS,进程信息是非常重要的数据。驭龙HIDS有一篇文章(https://xz.aliyun.com/t/2242)写到:
Linux上的HIDS需要实时对执行的命令进行监控,分析异常或入侵行为,有助于安全事件的发现和预防。为了获取执行命令,大致有如下方法:
- 遍历/proc目录,无法捕获瞬间结束的进程。
- Linux kprobes调试技术,并非所有Linux都有此特性,需要编译内核时配置。
- 修改glic库中的execve函数,但是可通过int0x80绕过glic库,这个之前360 A-TEAM一篇文章有写到过。
- 修改sys_call_table,通过LKM(loadable kernel module)实时安装和卸载监控模块,但是内核模块需要适配内核版本。
综合上面方案的优缺点,我们选择修改sys_call_table中的execve系统调用,虽然要适配内核版本,但是能100%监控执行的命令。
实际上是遗漏了接入成本最低的 audit。前一段时间,点融SRC的黑阔们也开源了自己的HIDS -- AgentSmith HIDS。
我们采用了通过加载LKM来实现Hook execve,connectinit_module,finit_module 的system_call,execve是为了捕获执行的命令来监控异常操作,归档等;监控connect是为了捕获服务器的网络行为,不仅仅可以发现很多安全问题,也可以方便的和AgentSmith-NIDS联动;监控init_modle和finit_module是为了监控加载LKM的行为,可以在这个层面做一些Anti-Rootkit的检测。
为什么要在内核态实现这些Hook呢?
因为我们希望可以尽可能的全面的收集以上信息,避免被绕过。而且在这里做Hook如果将来需要做一些危险命令等拦截也成为了可能,如:rm -rf /等。我们认为,越接近底层,离真相越近。
关于性能,我们为了尽可能的减少系统负载,放弃了最开始的传输方案:netlink,改用共享内存的方式来实现内核态到用户态到消息传输,经过测试对Hook的system_call的性能影响相较于netlink降低30%左右(更加详细的性能测试报告请见项目内)。
实现方式与驭龙HIDS的方式相同。我个人观点,越接近底层越危险。业务需要安全,更需要SLA稳定性,安全往往也背不起那么大的锅。
Audit 当然不是完美的存在,也有自己的运行损耗。在使用 auditd 的时候,性能消耗(主要为CPU)会随着进程量的提升有所上升,甚至到达单核50%-100%。同理,在本身负载较高的机器上,osquery 连接 audit 的时候,也会出现占用CPU较多的问题。
最早手写 Agent 的时候,就是通过 Audit 去实现的进程监控。本身进程大的时候,audit处理的时间就会比较长,再加上还要有查询其他系统资产的步骤(比如,追溯父进程信息,判断是否存在漏洞等等),就导致在部分机器上的资源占用过高。
当时的解决方案是在 Agent 代码中添加进程白名单,现在想来太过局限了。Audit 本身提供了一些白名单过滤的功能:
auditctl
-F [n=v | n!=v | n<v | n>v | n<=v | n>=v]
建立规则字段: 名称,操作,参数.一个命令行可以有64个字段,每个字段必须以-F开头.每个字段将会
触发一个audit记录.有=,!=,<,>,<=,>=运算符可以使用.
可以使用的字段有:
a0, a1, a2, a3, arch, auid, b32, devmajor, devminor, egid, euid, exit, fsgid, fsuid, gid, inode, key, msgtype, obj_user, obj_role, obj_type, obj_lev_low, obj_lev_high, path, pers, pid, ppid, subj_user, subj_role, subj_type, subj_sen, subj_clr, sgid, success, suid, uid
比起在 Agent 中添加白名单的方式,这种通过调整 audit 配置来实现的白名单,效率更高,从源头上解决占用资源过多的问题,而不是等日志经过一系列处理之后,再想办法过滤掉。
当然这只是 audit 占用资源过高的解决方案,为了尽可能减少 Agent 在线上运行的时候对业务的影响,我们还要有兜底方案,给资源占用加上硬限制,绝对不能超过指定值。
0x03 Agent性能保障
我们从三个方向去评估 Agent 对机器的性能影响:
- CPU
- 内存
- 磁盘
对 内存 和 CPU 的硬限制,是通过 CGroup 来实现。CGroup 在 centos7 下默认安装,可以通过 mount 命令来查看
$ mount | grep cpu
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
直接在 /sys/fs/cgroup/cpu 目录下新建文件夹,即可添加相应的规则。比如添加单核 20% CPU的限制规则:

将进程的 pid 写入到 cgroup.procs 后,即可实现对进程及其所有子进程的 CPU 限制。
当然实际使用的方式会更优雅,CentOS7 systemd 提供了对 CGroup 的支持,有需求的盆友可以自行搜索一下~
对磁盘的限制,主要是针对 /var/log/osquery.db/ 目录,也就是 RocksDB 的数据目录进行限制。目前对进程的磁盘占用,并没有很好的解决方案,只能通过挂载磁盘的方式间接实现。
# 生成十个100M的文件
dd if=/dev/zero of=disk.img bs=100M count=10
# 把生成的文件虚拟为块设备
losetup /dev/loop0 disk.img
# 格式化设备
mkfs.ext4 /dev/loop0
mkdir /osquery
# 挂载
mount disk.img/osquery
# 卸载
umount testdit
# 卸载loop设备与文件的关联
losetup -d /dev/loop0
这种方式的缺点是单独挂载的磁盘空间只能由 OSQuery 使用,即无论日志是 1M 还是 10M,都相当于占用了机器 1G 的空间。
是否实施磁盘限制的方案,需要根据业务的实际情况再做判断。
0x04 Server
Agent 搞定后,就涉及到了“如何更新配置文件”的问题。OSQuery支持两种模式:
- 本地读取,以json形式存在文件中即可
- 远端读取,通过 https 协议拉取配置
第一种方案,修改完 json 文件后,需要重启 OSQuery 进程才能读取到最新的配置。第二种方案的话,可以做到热更新,准实时读取/更新配置文件(拉取间隔时间可以配置),甚至可以对机器进行分组,分发不同的规则。这么牛逼的功能,不用是傻子。
之前也提到了,OSQuery 本身只是个 Agent,FaceBook 没有开源自己 Server 端的代码。官方文档中提供了几个第三方开发者开源的 Server:
其中,windmill 开发者删除了自己的项目(还好没用).....
zentral 是一个大型的监控软件,功能很多很乱,以至于我竟然没看懂它到底怎么用。fleet是长得最好看的,还提供了在线版的预览,对测试使用非常友好。doorman页面非常朴素,功能丰富,技术栈也非常匹配(python flask),最终选择了它。
具体的安装配置可以参考:INSTALL/SETUP DOORMAN + OSQUERY ON WINDOWS, MAC OSX, AND LINUX DEPLOYMENT
Doorman 主要功能包括:
- 通过tag管理机器(分组),一台机器可以对应多个tag
- 可以查看单个节点的概况,包括注册时间、执行的语句等
- 提供告警编辑页面,可以编辑告警规则
- 日志也可以通过 tls 进行收集,默认存储在 Postgres,也可以存到 ES 里
- 提供管理页面授权登录
- 实时下发单次执行的语句,并提供页面展示结果。
但是,doorman本身的设计算不上非常优秀。当 Agent 到达一定量之后,很可能出现并发量的瓶颈。重构/重写,就看各位大爷的心情了。
第一篇完结,第二篇会分享一些规则及后端数据分析的内容,敬请期待。更多问题,欢迎微博私信联系 @吃瓜群众-Fr1day。